从AlphaGo战胜柯洁,到无人驾驶的推进。AI时代离我们越来越近了。公司、项目只要和“人工智能”联系上就显得特别代表未来。
到底什么是"AI"呢。
关于AI,吴军有一本《智能时代》,李开复有一本《人工智能:李开复谈AI如何重塑个人、商业与社会的未来图谱》。两本书都很好,吴军的更偏科普一些,更多谈的是“信息熵”之类的科学原理。李开复这本视野更宏大一些,更多着眼于什么是AI,AI的进展,对商业的价值,对社会的挑战。
如果要挑着看一本书的话,我推荐李开复这本。
大数据和人工智能带来的各种科技体验已经涉及到方方面面:智能助理、新闻撰写、购物推荐、人脸识别、机器翻译、自动驾驶等等。
但是人工智能同样有危险,这本书在2017年5月出版,书中提到:
需要注意的是,大数据和人工智能的结合也可能给信息流通和社会公平带来威胁。在2016年的美国大选中,有一家名为Cambridge Analytica的公司就基于人工智能技术,用一整套分析和引导舆论的软件系统来操纵选情。这个系统可以自动收集和分析互联网上的选情信息,评估人们对两位总统候选人的满意度,并通过给定向用户投放信息,自动发送虚假新闻等技术手段,宣传自己所支持的候选人,还可以通过A/B组对照试验,准确判断每个州的选民特征,为自己所支持的竞选团队提供第一手的数据资料和决策依据。Cambridge Analytica的投资人是特朗普的“金主”,因此Cambridge Analytica在大选中就主要为特朗普服务。特朗普战胜希拉里后,美国伊隆大学的助理教授兼数据科学家乔纳森·奥尔布赖特(Jonathan Albright)开始研究大选中的假新闻和舆论引导内幕,他不无忧虑地说:“这简直就是台宣传机器。它一个个地拉拢公众,使他们拥护某个立场。如此程度的社会工程,我还是头一次见。他们用情绪作为缰绳,套住人们,然后就再也不松手了。2018年3月17日,英国《卫报》爆出英国的数据分析公司Cambridge Analytica(剑桥数据分析)的数据来源于非法获取的Facebook的用户信息,涉及到的用户人数高达五千万人,这被称为是“Facebook历史上最大的数据泄漏事件”。
在大数据发挥作用的同时,人工智能研发者也一定不要忘了,大数据的应用必然带来个人隐私保护方面的挑战。为了给你推送精准的广告信息,就要收集你的购买习惯、个人喜好等数据,这些数据中往往包含了许多个人隐私;为了获得以人类基因为基础的医疗大数据来改进疾病的诊疗,就要通过某种渠道收集尽可能多的人类基因样本,而这些数据一旦保管不善,就可能为提供基因样本的个人带来巨大风险;为了建立智能城市,就要监控和收集每个人、每辆车的出行信息,而这些信息一旦被坏人掌握,往往就会成为案犯最好的情报来源…… 有效、合法、合理地收集、利用、保护大数据,是人工智能时代的基本要求,需要政府、企业、个人三方共同协作,既保证大规模信息的正常流动、存储和处理,又避免个人隐私被滥用或被泄露。我们每个人都在享受智能时代带来的各种便利,但同时我们也需要更了解这个智能是如何而来,这有助于我们理解这个技术、这个时代。
今天介绍的书中的内容,到底什么是AI
人工智能之所以在今天这个时代突飞猛进,不是因为在基础理论上获得了多个重大突破,而是今天终于实现了过往的时代都不具有的利器:大计算能力以及海量数据。
本质上今天所有人工智能的呈现都只是在各个领域建立模型,然后进行深度学习的结果。
用专业的术语来说,计算机用来学习的、反复看的图片叫“训练数据集”;“训练数据集”中,一类数据区别于另一类数据的不同方面的属性或特质,叫作“特征”;计算机在“大脑”中总结规律的过程,叫“建模”;计算机在“大脑”中总结出的规律,就是我们常说的“模型”;而计算机通过反复看图,总结出规律,然后学会认字的过程,就叫“机器学习”。书中举了例子来帮助我们理解什么叫做“建模”和“机器学习”。
简单地说,深度学习就是把计算机要学习的东西看成一大堆数据,把这些数据丢进一个复杂的、包含多个层级的数据处理网络(深度神经网络),然后检查经过这个网络处理得到的结果数据是不是符合要求——如果符合,就保留这个网络作为目标模型,如果不符合,就一次次地、锲而不舍地调整网络的参数设置,直到输出满足要求为止。1.计算机分辨“一”“二”“三”“口”“田”的决策树
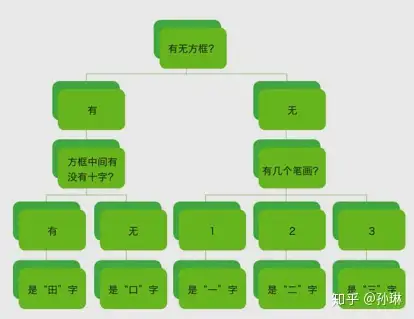
2.计算机学习了“由”“甲”“申”三个新汉字之后的决策树

3. 用“水管网络”来描述教计算机识字的深度学习过程
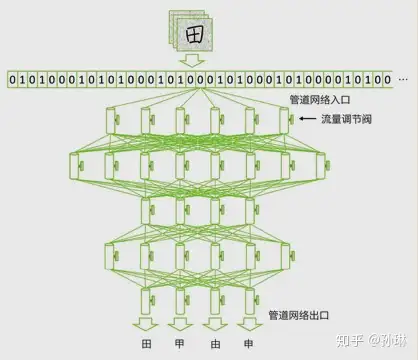
当计算机看到一张写有“田”字的图片时,就简单将组成这张图片的所有数字(在计算机里,图片的每个颜色点都是用“0”和“1”组成的数字来表示的)全都变成信息的水流,从入口灌进水管网络。 我们预先在水管网络的每个出口都插一块字牌,对应于每一个我们想让计算机认识的汉字。这时,因为输入的是“田”这个汉字,等水流流过整个水管网络,计算机就会跑到管道出口位置去看一看,是不是标记有“田”字的管道出口流出来的水流最多。如果是这样,就说明这个管道网络符合要求。如果不是这样,我们就给计算机下达命令:调节水管网络里的每一个流量调节阀,让“田”字出口“流出”的数字水流最多。
下一步,学习“申”字时,我们就用类似的方法,把每一张写有“申”字的图片变成一大堆数字组成的水流,灌进水管网络,看一看,是不是写有“申”字的那个管道出口流出来的水最多,如果不是,我们还得再次调整所有的调节阀。这一次,要既保证刚才学过的“田”字不受影响,也要保证新的“申”字可以被正确处理。
如此反复进行,直到所有汉字对应的水流都可以按照期望的方式流过整个水管网络。这时,我们就说,这个水管网络已经是一个训练好的深度学习模型了。
深度学习大致就是这么一个用人类的数学知识与计算机算法构建起整体架构,再结合尽可能多的训练数据以及计算机的大规模运算能力去调节内部参数,尽可能逼近问题目标的半理论、半经验的建模方式。 指导深度学习的基本是一种实用主义的思想。
实用主义意味着不求甚解。即便一个深度学习模型已经被训练得非常“聪明”,可以非常好地解决问题,但很多情况下,连设计整个水管网络的人也未必能说清楚,为什么管道中每一个阀门要调节成这个样子。也就是说,人们通常只知道深度学习模型是否工作,却很难说出模型中某个参数的取值与最终模型的感知能力之间,到底有怎样的因果关系。 这真是一件特别有意思的事。有史以来最有效的机器学习方法,在许多人看来,竟然是一个只可意会、不可言传的“黑盒子”。
也就是说我们知道一个模型有用与否,只能看结果。到底过程是怎样的,设计的人也不太知道。人工智能就是一个用大数据与机器学习相结合,输出结果的黑盒子。(讲真,我感觉这点有点象中药(捂脸)……)
好啦,讲到这里,我们差不多理解AI是咋回事了。所以呢……
1. 终于明白之前Facebook的恐慌,因为研究人员建模之后,如果输出了意料之外的结果,也搞不清是怎么回事啊。(比如是出了岔子,还是机器突然具有了“智能”)

2. 虽然现在AI概念很火,但是其实能够得到快速进展的,一定是有大数据作为支撑的领域。
比如医疗领域,为什么影像AI进展很快,就是因为有大量数据可供机器学习。换而言之,没有大数据的领域,进展不可能很快。李开复也说,我们距离电影中的科幻人工智能还很远,就是因为本质上这一波AI发展只是建立在机器学习这一个基础研究突破上。
3. 与我们息息相关的——隐私
大数据杀熟是什么呢——是指同样的商品或服务,老客户看到的价格反而比新客户要贵出许多的现象。
相类似的,之前电影票购票平台苹果手机终端购票会贵几块钱;
甚至,淘宝化妆品卖家会根据买家过往的购物经历及货值判断买家是否有过真品使用体验来选择性发真货还是假货;
电商法出台,所有的焦点都在代购要缴税上,电商法也明确了不允许大数据杀熟以及对隐私的保护,算是很大的进步。
4. 最后,整个AI都是由数据驱动的,所有的平台都对数据很“饥渴”
算法成为各个公司的核心机密,不予公开。同时谁掌握更多的数据,就能在AI领域更胜一筹。掌握更多数据,就能将模型训练的更“智能”,比如更智能的推荐产品、更智能的发送广告、更有针对性的卖出产品。
理解整个前提,就能理解所有公司对海量数据的渴望。
为什么从亚马逊到苹果,百度到阿里,都开始卖智能音箱了?
有组织研究发现,即使用户认为智能音箱在“休眠”的状态时,它们也可以被“唤醒”。实际上,这些设备只要开着,就一直都在收听声音。而亚马逊则设想用语音助手Alexa收集信息,并建立房间里内的任何人的档案,并依此向其推销相应产品。
据悉,亚马逊提交了一个算法专利申请,该算法可使未来的智能语音设备识别有关兴趣的语句。比如用户说“我喜欢滑雪”,设备便可通过扬声器进行监听,并针对这一喜好推荐相关广告。而谷歌的专利申请则描述了未来智能家居系统监视家庭一切活动的场景。根据该专利描述,设备可获取多种信息,无论是家庭成员对电视节目的喜好,还是他们的卫生习惯,都可以通过这项相关新技术获取。
该组织的隐私和技术项目总监约翰·辛普森表示:“谷歌和亚马逊公司希望你们认为,他们的智能家居设备能够用你的声音帮助你。但实际上,他们在家里窥探你和你的家人,并尽可能地收集你的活动信息。”所以你觉得智能音箱是仅仅为了帮你方便的听歌么?
